
In the last five years, the use of AI and Machine Learning in security turned from an interesting novelty to be part of the mainstream. Small and large vendors started offering products and features that utilize clever Machine Learning methods to improve security. Every solution out there says it will help catch the next attacker – I know we do - but that’s a pretty bold claim to make. How do you verify if there’s any truth behind it?
However the engineer in me starts to twitch and scratch and feel uneasy if it does not get precision, definitions and proofs. That precision is a must-have if you want to decide if your product is useful – and to decide if the product you plan to buy will do what you need it to do.
You cannot quantify something without hard data, and no matter what the news says, real attacks are extremely rare compared to business-as-usual activities. To make things worse, those breached are unlikely to share information, let alone raw data, about how that happened. Of course, detecting attacks that happened in the past say little about our ability to find things that will happen in the future. So what can you do without that data sample?
One option is to identify your own nightmare scenarios, simulate them and check if analytics could identify them. It’s an important step, I would even call it due diligence. However, it has a critical flaw: you will only ever test attack scenarios that you could think of and ones that you were able to simulate.
Neither is true for most dangerous attacks you will experience: the “unknown unknowns” will remain in your blind spot, and advanced technologies like Machine Learning are often introduced precisely to go beyond what can be covered with single rules covering well-known scenarios.
Any organization has tons of data about its internal users. The technique of cross-scoring is a fantastic way to make use of that data. To understand how it works, think about the primary goal of user behavior analysis tools: identify if it’s the same person behind the keyboard doing what he or she usually does and alert if they don't. Or, using textbook language, if it’s really Alice doing things and not Mallory, the malicious attacker, using Alice’s credentials. The problem is, we don’t have many true Mallories recorded but we do have lots of Bob. Let’s make them work.
The process goes as follows. Take a bunch of activity information from three perfectly average and well-meaning folks in the organization, Alice, Bob and Cecil.
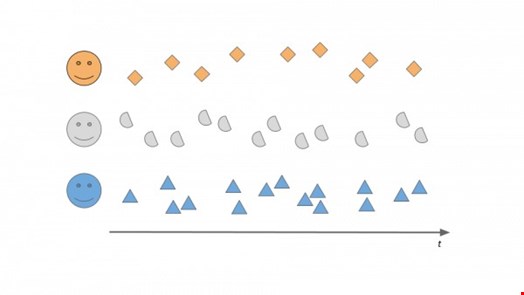
Now let's split the historical data we have about them into two parts: training and test data and let's then use the training data and the algorithm or product we want to test to build a baseline of what's typical, what's business-as-usual for Alice, Bob and Cecil. Let's learn when are they active in a day, which applications they are using, what data they are accessing, how are they typing – whatever the given product or algorithm does.
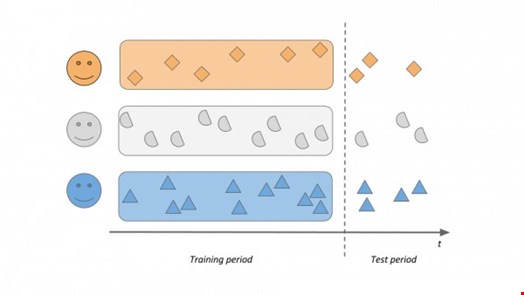
Then use the same algorithm or product to start scoring. First, take Alice's activities from the test period and see what scores they'd get. We expect those to be low, as this is good old Alice doing what she does every day, nothing to see here. Then let's take Bob's activities and see how they would be scored if they were done by Alice. If Alice and Bob are not the same person doing the exact same things every day, we expect those scores to be much higher – Bob has basically hijacked Alice's account! Let's do the same with Cecil's activities and then the other way around, compare all activities with one's own and everyone else's baselines.
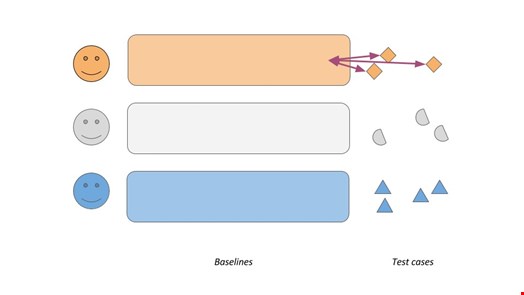
This gives us lots of scores, and we expect Alice's own activities to be scored low and the "intruder" activities taken from Bob's actions to be high. How could this be done depends a lot on the product in question, but it’s usually much easier to just change the usernames on normal activity records than to simulate complex attack scenarios.
There are several methods to quantify the results. As part of our product’s built-in self-evaluation feature, we define and measure complex metrics, but simply visualizing the scores in Excel and eyeballing the results is more than enough in most cases: did “intruders” systematically get a higher score than normal users? If they did, the solution works. If they don’t - well, the fairy dust did not do its magic this time.
One thing is for certain: you must not trust any algorithms blindly. Trying to find real-life, usable attack data samples to do tests is tempting, but don’t bother – they don’t exist. You must verify every solution's performance on your own dataset, either by simulating attacks or utilizing your existing data and the trick of cross-scoring. AI can do wonders. But believe nothing but your own eyes.