
Large language models (LLMs) are increasingly used for cyber defense applications, although concerns about their reliability and accuracy remain a significant limitation in critical use cases.
A team of researchers from the Rochester Institute of Technology (RIT) launched CTIBench, the first benchmark designed to assess the performance of LLMs in cyber threat intelligence applications.
“LLMs have the potential to revolutionize the field of CTI by enhancing the ability to process and analyze vast amounts of unstructured threat and attack data, allowing security analysts to utilize more intelligence sources than ever before,” the researchers wrote.
“However, [they] are prone to hallucinations and text misunderstandings, especially in specific technical domains, that can lead to a lack of truthfulness from the model. This necessitates the careful consideration of using LLMs in CTI as their limitations can lead to them producing false or unreliable intelligence, which could be disastrous if used to address real cyber threats.”
Although there are already LLM benchmarks in the market, these are either too generic (GLUE, SuperGLUE, MMLU, HELM) to objectively measure cybersecurity applications or too specific (SECURE, Purple Llama CyberSecEval, SecLLMHolmes, SevenLLM) to apply the cyber threat intelligence.
This lack of ad-hoc LLM benchmark for CTI applications led the RIT researchers to develop CTIBench.
What is CTIBench?
The researchers described CTIBench as “a novel suite of benchmark tasks and datasets to evaluate LLMs in cyber threat intelligence.”
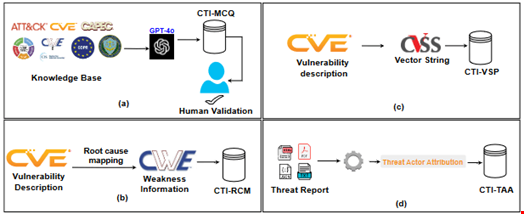
The final product is composed of four building blocks:
- Cyber Threat Intelligence Multiple Choice Questions (CTI-MCQ)
- Cyber Threat Intelligence Root Cause Mapping (CTI-RCM)
- Cyber Threat Intelligence Vulnerability Severity Prediction (CTI-VSP)
- Cyber Threat Intelligence Threat Actor Attribution (CTI-TAA)
Creating Multiple-Choice Questions Using GPT-4
The first step in the CTIBench development process consisted of creating a knowledge evaluation database.
To create this database, the researchers collected data from a range of authoritative sources within CTI, such as the US National Institute of Standards and Technology (NIST) cyber frameworks, the Diamond model of intrusion detection and regulations like the European General Data Protection Regulation (GDPR).
This knowledge database helped them create multiple-choice questions to assess the LLMs’ understanding of CTI standards, threats, detection strategies, mitigation plans and best practices.
The researchers formulated questions using CTI standards like STIX and TAXII, CTI frameworks like MITRE ATT&CK and the Common Attack Pattern Enumerations and Classifications (CAPEC), and the common weakness enumeration (CWE) database.
They then generated the final list of multiple-choice questions using GPT-4 and manually assessed and validated it.
The final dataset consists of 2500 questions, of which 1578 were collected from MITRE, 750 from CWE, 40 from the manual collection and 32 from standards and frameworks.
Root Cause Mapping, Vulnerability Severity Prediction and Attribution
With CTIBench, the researchers proposed two practical CTI tasks that evaluate LLMs’ reasoning and problem-solving skills:
- Mapping common vulnerabilities and exposures (CVE) descriptions to Common CWE categories (i.e. CTI-RCM)
- Calculating the severity of vulnerabilities using common vulnerability scoring system (CVSS) scores (i.e. CTI-VSP)
Finally, they provided a tool asking the LLM to analyze publicly available threat reports and attribute them to specific threat actors or malware families (i.e. CTI-TAA).
ChatGPT 4 Best Performing LLM Tested with CTIBench
They tested five different general-purpose LLMs using CTIBench: ChatGPT 3.5, ChatGPT 4, Gemini 1.5, Llama 3-70B and Llama 3-8B.
ChatGPT 4 received the best results for all tasks except vulnerability severity prediction (CTI-VSP), for which Gemini 1.5 was the best-performing model.
Despite being open-source, LLAMA3-70B performs comparably to Gemini-1.5 and even outperforms it on two tasks, though it struggles with the CTI-VSP task.
“Through CTIBench, we provide the research community with a robust tool to accelerate incident response by automating the triage and analysis of security alerts, enabling them to focus on critical threats and reducing response time,” the researchers concluded.
Read more: How Cyber Threat Intelligence Practitioners Should Leverage Automation and AI