Here we are, more than 20 years after the introduction of Linux, and security around open source is still misunderstood. Misconceptions still prevail from the days when open source was considered a hobbyist’s pursuit; let’s dispel some of them by looking at common myths on security related to open source and realities around risk mitigation.
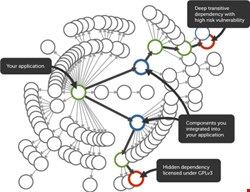
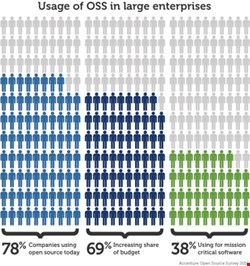
The truth of the matter is that most modern software applications can’t avoid using open-source software – it is simply not possible in agile environments where applications are assembled from existing frameworks, libraries and components.
Misconception: With So Many Reviewers, Open Source Is Definitely Secure
Although it’s true that the ability to access the code base is open to all, open-source communities have mechanisms in place to ensure peer review. This is true in software and in other communities of contribution – think Wikipedia. Anyone with an account can make radical edits to a Wikipedia page, but it will eventually be caught by the site’s editors and taken down. Taking it a step further than text edits on Wikipedia, popular open-source projects also have a community of users who scrutinize all contributions. There is too much at stake to the community to let risky or ill-designed code into the mix.
The same goes for the discoverability of flaws. In a closed-source system, remedies come from one place – the organization that authored the code. Open source allows for a distributed review; error checking and patching happens relatively quickly. When flaws are identified – and fixed – everyone benefits with both information around the nature of the flaw, but also the details of remediation.
The problem is that peer review is not enough. Flawed open-source components have a tendency to seep into mission-critical applications at an alarming rate – 71% of applications contain flawed components classified as severe or critical. This is largely due to the lack of a centralized update notification infrastructure for open-source components and the complexity of a highly distributed software supply chain.
It wouldn’t be prudent to leave your business systems in the hands of a community without some checking of your own. Self-monitoring is a good precaution, particularly when it comes to components and frameworks. Look for vendor solutions that proactively monitor component use during the entire software development lifecycle and once applications go into production.
Myth: It’s too Late for Us to Start
More than 80% of a typical application is assembled with components; no one is in a position to start from scratch. It’s not too late though. Begin by creating an inventory of what you have in your applications and development repositories.
I know – this sounds easier than it is. But you have to start the process somewhere, and the best way to begin is by taking inventory. You can’t begin to put a strategy in place for remediation if you don’t even know what you have.
The fact remains that most organizations don’t know exactly what applications they are running, let alone a list of components driving them. Focus on the highest-priority applications or repositories – the ones that are mission critical – and build an inventory of intelligence from there.
Misconception: I’m in Development; We Have People for Security
You have a security department – they should take care of security and your developers should just focus on delivering the features, right?
Wrong.
Developers are the first line of defense against application attacks. You need to integrate security analysis and flaw remediation into the development process. It’s tough, because developers won’t always embrace this new responsibility. The key is to give them the information and tools that improve security without disrupting the way they do their jobs.
While we’re on this topic, what about open-source policy? About half of organizations have some sort of open-source policy. This is a good start, but how is it enforced? Most companies have no enforcement whatsoever, leaving the organization at the whim of opt-in compliance and exposing it to unnecessary risk.
Misconception: We Scan Our Source Code, So We Should Be Able to Detect and Correct All Flaws
Well, not exactly. Source code scanning can be effective, especially for your custom code, but what about the 80% of your application that is made of open-source components and frameworks? And when do you run your scans? Most organizations run source code scans at the end of development – when fixes are expensive. Oftentimes, ‘just push it to production’ wins out over ‘let’s be sure we’re secure.’
Myth: Open Source Is Impossible to Secure
This is perhaps the biggest myth of all; it’s not impossible to secure open-source software, but it takes effort. A layered approach to security not only at the end of the lifecycle, but at each phase – at consumption, in development, during integration, and within production – decreases threats and leads to a more rapid response time.
Ryan Berg is CSO of Sonatype, which specializes in component lifecycle management. Berg was also the former Cloud security strategy lead at IBM.