
Anthropic’s latest frontier large language models (LLMs), Claude Mythos 5 and Claude Fable 5, are available again – but with added security limitations.
On June 30, just 19 days after the US government enacted export controls on both models which forced Anthropic to suspend their global distribution, the decision was lifted.
The same day, the AI lab announced it was redeploying both models from July 1.
However, they will now come with additional limitations aimed to address AI safety and security concerns raised by the US government.
Fable 5 Equipped With New US-Approved Safeguards
Fable 5, a general-access LLM powered by the same underlying frontier AI model as Mythos 5 – itself an upgrade from Claude Mythos Preview – is now available to users globally across all the Claude Platform, Claude.ai, Claude Code and Claude Cowork.
For premium users who have subscribed to Pro, Max, Team and select Enterprise plans, the model will be included for up to 50% of weekly usage limits through July 7, after which it will be available via usage credits.
Anthropic is also rolling out availability of the general-access model on AWS, Google Cloud and Microsoft Foundry.
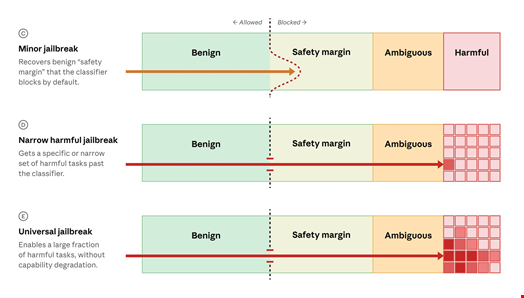
The AI company confirmed it had reviewed the Amazon report that prompted the export control directive. In the report, researchers had found a jailbreak, a method of prompting Fable 5 so that it identified software vulnerabilities and, in one case, provided an exploit – therefore bypassing the model’s built-in safeguards.
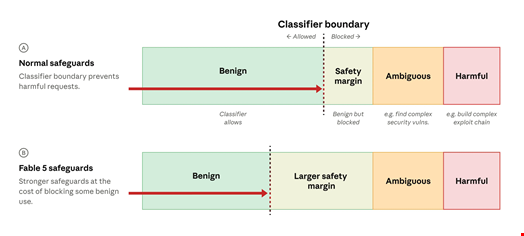
While Anthropic said that the reported technique “did not expose any unique Mythos-level cyber capabilities,” the company is releasing a new version of Fable 5 equipped with “an improved safety classifier that targets and blocks the behavior described in the report.”
A classifier is a small, automated AI systems that, during an interaction with an LLM, detects when the model is asked to perform a potentially harmful task or to produce potentially harmful outputs and then blocks it from responding to requests.
According to Anthropic, the new classifier blocks the jailbreak identified by Amazon researchers “in over 99% of cases.”
It may, “in a very small fraction of cases,” provide information after a potentially harmful user request but Anthropic claimed it wouldn’t be “detailed enough to help a cyber attacker.”
“The model’s safeguards are not expected to block all low-risk routine cyber defense capabilities – just those that are potentially harmful,” said the company.
When a request to Fable 5 is blocked, the users will be notified that it has been redirected to Opus 4.8.
“The new classifier also comes at the cost of flagging benign requests more often during routine coding and debugging tasks,” Anthropic admitted. It said it would continue to refine the safeguards to better distinguish genuine misuse from legitimate requests and reduce false positives.
Anthropic said researchers from the US Department of Commerce’s Center for AI Standards and Innovation (CAISI) have tested the new safeguards and described them as “extraordinarily strong.”
Anthropic Teams Up with Government and Industry to Accelerate AI Security
Before lifting export controls on Fable 5 and Mythos 5 on June 30, the US government approved Mythos 5 to be redeployed to a set of US organizations that operate and defend critical infrastructure.
“We continue to coordinate with the government to expand access to the broader set of domestic and international partners in the Glasswing program,” Anthropic noted.
The company also said it was collaborating with the US government to accelerate AI security, including via pre-deployment testing and evaluation.
In the meantime, the AI lab has worked with Amazon, Microsoft, Google and other Glasswing partners to draft a consensus framework for assessing the severity of AI jailbreaks – including finding a standard definition of what constitutes a “universal jailbreak” – and how AI developers should respond to them.
Finally, the AI lab has launched a new HackerOne program where security researchers can submit potential cyber jailbreaks they’ve discovered in Fable 5 for review.
Image credits: wutianzeri / RixAiArt / Shutterstock.com